Retrouvez ici les questions les plus fréquentes à propos de notre plateforme My Ranking Metrics, en particulier de RM Tech. Nous les avons regroupées par thématiques :
Si vous avez d’autres questions, posez-les dans le formulaire de contact.
RM Tech
Lancement d’un audit
Peut-on limiter le nombre d’URL d’un audit ?
Oui, vous pouvez décider de limiter l’audit à une partie seulement du site en vous basant sur le nombre d’URL crawlées. Voici comment faire, dans la dernière étape du lancement de l’audit :

Attention : c’est dommage d’avoir un audit incomplet (car toutes les URL du site n’ont pas été crawlées donc étudiées). Mettez une limite « basse » quand vous êtes certain de vouloir vraiment restreindre, en sachant que l’audit sera partiel. Voyez nos conseils ci-dessous, avec le sujet sur le décompte du nombre de crédits par audit.
Vous pouvez aussi limiter en définissant des motifs d’inclusion et d’exclusion basés sur les URL.
Comment savoir combien d’URL prévoir pour faire un audit ?
Ce n’est pas évident de savoir combien d’URL vont être crawlées (explorées, trouvées) sur un site. Ce nombre est souvent supérieur à ce qu’on peut croire initialement, car on a tendance à oublier des URL qui existent (Google les trouvera…) mais qui ne sont pas des « vraies » pages (par exemple de la pagination ou des tris).
Idem pour le nombre d’images !
Le plus simple est de faire un pré-audit RM Tech (gratuit) : le nombre d’URL et d’images trouvées est indiqué en haut du rapport.
Voyez aussi les explications complètes sur WebRankInfo : comment savoir combien d’URL prévoir pour un audit SEO ?
Comment choisir le nombre maximal d’URL à explorer ?
D’abord, évaluez combien il y a d’URL à explorer sur votre site (cf. ci-dessus).
Si c’est uniquement une estimation (car vous n’avez encore fait aucun audit), nous vous conseillons de choisir comme nombre d’URL maximal à crawler un nombre « largement supérieur » à votre estimation. Par exemple, ajoutez 30%, ou 50%, voire beaucoup plus pour vous assurer que l’audit soit exhaustif.
Si vous estimez qu’il y a 1000 URL à crawler, indiquez par exemple 1500 ou même 5000 pour être vraiment sûr.
Si vous mettez un nombre trop proche de votre estimation, vous prenez le risque qu’en réalité il y ait un peu plus d’URL que ça à crawler et donc que votre audit ne soit pas complet. Voici le genre d’avertissement que vous pouvez trouver en haut de votre rapport d’audit :

Je reprends mon exemple avec une estimation de 1000 URL. Supposons que vous indiquiez 1000 URL max à crawler et que dans le rapport on vous indique que l’audit est incomplet car l’outil s’est arrêté à 1000 comme demandé, mais qu’il y avait d’autres URL. alors, vous ne saurez pas si le site a en réalité 1001 URL, ou 1200, ou même 5000… Ce serait vraiment dommage d’avoir un audit incomplet alors qu’il ne restait peut-être pas tant que ça d’URL à crawler.
Quel rapport entre le nombre de crédits et le nombre maximal d’URL à explorer ?
L’outil est basé sur le fait qu’un crédit est compté pour chaque URL crawlée.
Pour comprendre le décompte des crédits, voici un exemple concret :
- au moment de lancer un nouvel audit, vous disposez de 8000 crédits
- vous estimez que le site à auditer contient 1500 URL
- vous prenez de la marge, vous indiquez 5000 URL max à crawler
- dès que vous validez le lancement, l’outil vous retire 5000 crédits, il vous en reste donc 3000
- pendant que l’audit tourne, vous pouvez lancer d’autres audits avec les 3000 crédits dont vous disposez
- quand l’audit est terminé, l’outil compte combien de crédits il faut réellement retirer : c’est le nombre d’URL effectivement crawlées
- dans cet exemple, l’outil a crawlé en réalité 1800 URL
- on vous « restitue » donc 5000-1800=3200 crédits
- il vous en reste donc 3000+3200=6200
- au final, sur les 8000 crédits que vous aviez, l’audit a réellement consommé 8000-6200=1800 crédits, c’est-à-dire exactement le nombre d’URL crawlées
Précisions : on compte un crédit pour chaque URL que l’outil a crawlée, quel que soit le résultat de ce crawl (erreur 404 ou pas, etc.). On ne compte pas les URL interdites au crawl (par le fichier robots.txt) mais pourtant identifiées. Lisez les détails en bas de page.
Quel est le problème des pages explorées dont le code dépasse le plafond de taille ?
RM Tech crawle au maximum 6000Ko de code HTML par page. Il s’agit du code HTML brut (une fois décompressé, si jamais le serveur le compresse). Ceci n’inclut aucune ressource de la page : ni les images, ni les javascript, CSS et autres.
C’est énorme et aucune de vos pages ne devrait être concernée par cette limite, loin de là. Si jamais c’était le cas, par exemple une page dont le code HTML fait 7000Ko, l’outil ne va se baser que sur le code HTML situé dans les 6000 premiers Ko. Si jamais dans les 1000 autres Ko il y a du contenu important pour la page, notamment des liens vers d’autres pages, alors l’analyse sera incomplète.
Par ailleurs, nous avons remarqué que Bing semble se limiter à environ 700Ko (Google n’a pas cette limite). C’est pourquoi dans le rapport, vous verrez en guise d’avertissement une indication du nombre de pages dont le poids dépasse 700Ko. Que faire si cela vous arrive ?
- consultez la liste des pages dont le poids du code dépasse 700Ko (en téléchargeant l’annexe en conclusion)
- si possible, optimisez votre site afin de réduire cette taille
Profondeur et maillage interne
Le rapport m’indique une profondeur de page supérieure à la réalité. Comment l’expliquer ?
Vous avez donc identifié une page A dont la profondeur indiquée vous semble trop grande, en tout cas plus que ce que vous trouvez manuellement ou avec un autre outil.
D’abord, essayez d’identifier précisément un exemple d’URL (notons-la B) qui fait un lien vers la page A, ce qui expliquerait selon vous que la profondeur de A est moindre que ce qu’indique le rapport.
Ensuite, étudiez bien les raisons suivantes qui peuvent expliquer la situation :
- la page B n’a pas été crawlée par RM Tech, ou bien avec une erreur (vérifiez qu’elle est bien listée parmi les pages HTML en code 200)
- le lien dans la page B est en nofollow
- le lien dans la page B pointe vers une URL intermédiaire C qui redirige vers A, mais C est interdite de crawl (par une instruction dans le fichier robots.txt correspondant)
- le lien dans la page B ne pointe pas exactement vers A, mais vers une URL contenant des paramètres supplémentaires affichant pourtant le même contenu que A
- le lien dans la page B n’existe que si on interprète le code Javascript (ce qui n’est pas fait dans l’audit)
- la page B est tellement grosse (taille du code HTML en Ko) qu’elle n’a pas été crawlée en entier (c’est indiqué dans le rapport) et le lien vers la page A est situé dans la partie non crawlée de la page
Le rapport m’indique que je n’ai pas assez d’ancres distinctes dans les liens entrants internes, pourtant j’en ai plusieurs. Comment l’expliquer ?
En général, vous oubliez de tenir compte du fait que, comme Google a priori, RM Tech ne tient compte que du 1er lien trouvé dans une page.
Si une page A fait un lien vers une page B dans le menu, et un autre lien toujours vers la page B dans le corps de la page, alors RM Tech ne tient compte que du 1er lien trouvé dans l’ordre du code source HTML. En d’autres termes, pour cet exemple, l’ancre du lien prise en compte est celle du lien situé dans le menu.
Analyse du contenu
Quel est le nombre minimum de mots par page conseillé par RM Tech ?
D’abord, il n’existe pas de nombre minimal ou idéal, surtout que ça dépend de l’objectif de la page et des intentions de recherches pour lesquelles la page est optimisée.
Ensuite, il ne faut surtout pas se baser sur le nombre total de mots dans la page : il n’est pas fiable (car il inclut la navigation, le haut de page, la barre latérale et le pied de page ainsi que la zone complémentaire). Notre algorithme tente de repérer la zone principale de la page.
Enfin, il faut tenir compte du type de page (par exemple il faut bien plus de mots pour un tutoriel que pour une fiche produit). C’est ce qui est fait par RM Tech.
Notre indice de gravité du problème de manque de contenu vous aide à classer les pages afin de fixer des priorités. (lisez ici l’article sur notre algorithme thin content)
Indices QualityRisk et Zombie
Pourquoi l’indice zombie n’a pas été calculé ?
L’analyse des pages zombies ne peut se faire que si nous disposons de toutes les données nécessaires pour cet algorithme spécifique. Il n’est pas nécessaire de faire le couplage avec Google Analytics, par contre il est indispensable de le faire avec Google Search Console. Vérifiez que votre audit a été fait dans ces conditions :
- il s’agit d’un rapport complet (pas gratuit)
- le couplage avec Google Search Console a été effectué sur 365 jours et les données ont pu être récupérées sans problèmes pour les pages à analyser
- le crawl a permis d’identifier des pages indexables autres que l’URL de départ (notez que certaines pages sont exclues de cette analyse, comme les mentions légales et autres pages spéciales)
Que signifie n/a pour l’indice zombie ?
Nous indiquons n/a dans les cas où la page semble être un cas particulier pour lequel l’indice zombie n’a pas de sens (par exemple l’URL de départ ou URL de la pagination). Il ne s’agit pas d’une erreur ou d’un problème technique.
Regardez par exemple si dans le code source de la page vous trouvez une balise link rel=next ou rel=prev (pagination).
Voir aussi : définition d’une page zombie et repérer les pages zombies d’un site
Comment optimiser l’indice QualityRisk ?
L’indice QualityRisk d’une page est un nombre entre 0 et 100 qui indique à quel point la page cumule des problèmes qui freinent ses performances SEO (sous un angle essentiellement technique).
L’annexe située en conclusion du rapport d’audit RM Tech liste toutes les pages indexables, avec pour chacune son indice QualityRisk. Pour une page donnée que vous souhaitez optimiser, regardez toutes les métriques listées dans les colonnes de ce fichier.
Pour vous aider, nous proposons un guide sur QualityRisk et Pages Zombies. En savoir plus.
Données Google Search Console et Google Analytics
Dans RM Tech, je n’arrive pas à activer l’option Google Analytics, c’est bloquant ?
Non ce n’est pas bloquant car RM Tech n’utilise pas les données de Google Analytics.
Par contre, les données de Google Search Console sont indispensables si vous souhaitez un rapport incluant les analyses avancées telles que les pages Zombies.
Que signifie n/a pour les données Search Console ?
Nous indiquons n/a dans les cas où aucune donnée n’a été fournie par l’API. Il ne s’agit pas d’une erreur ou d’un problème technique.
Par exemple, si le nb d’impressions générées par une page est n/a, cela signifie que cette page n’est jamais apparue dans les SERP sur la période concernée, selon Google Search Console.
En général, vous pouvez considérer que n/a signifie zéro.
Problèmes techniques SEO
Pourquoi faut-il une 404 personnalisée ?
La chose la plus importante est de vérifier que pour une URL introuvable, votre serveur renvoie un code 404. Il ne doit pas y avoir une redirection qui aboutit à une page 404, mais directement un code 404. Dans le cas contraire, cela perturbe fortement les analyses faites par les moteurs de recherche (ainsi que par notre outil). Vérifiez le code HTTP sur cet outil par exemple. Attention, cette règle est applicable à tous vos sous-domaines.
Le second point est qu’il est préférable d’avoir une page 404 personnalisée. Cela signifie que cette page doit reprendre le design général de votre site. La principale raison est de rassurer les internautes sur votre site (sinon ils risquent de le quitter immédiatement). La seconde raison est que nos algorithmes se basent sur tous les types de pages, y compris cette page 404. Si vous n’avez pas de 404 personnalisée, les analyses dans RM Tech et RM Sitemaps sont perturbées (et parfois, l’évaluation sur la taille des contenus est instable d’un audit à un autre).
Vous trouverez sur WebRankInfo des conseils pour faire une page 404 personnalisée, dont voici un résumé :
- utilisez le même modèle de page que sur le reste du site (avec l’entête, le menu, le pied-de-page et éventuellement une barre latérale)
- au centre de cette page, mettez un texte d’explications et si possible un formulaire de recherche interne
- au total, cette page devrait contenir au moins 50 à 100 mots minimum et au moins une dizaine de liens (des liens vers d’autres pages du site)
A quoi correspond l’erreur « Aucun code HTML valide trouvé » ?
Il s’agit de pages dont le code HTML n’est pas valide, par exemple des pages qui ne contiennent pas la balise <html>.
Pourquoi RM Tech signale que ma page /index.html n’est pas indexable à cause de son URL canonique ?
Notre outil (comme Google) se base sur les URL, c’est-à-dire ce qui est accessible de l’extérieur et non pas les noms des fichiers utilisés par votre serveur. Prenons l’exemple d’une page d’accueil https://www.example.com/ pour laquelle RM Tech indique des problèmes d’URL canonique.
Que la page d’accueil soit gérée par le fichier /index.html ou /index.php ou autre chose ne change rien, ce qu’il faut c’est que vos liens vers votre page d’accueil pointent vers https://www.example.com/ et non pas vers https://www.example.com/index.html. Et de la même façon, que l’URL canonique indiquée soit bien l’URL publique (https://www.example.com/ dans cet exemple) et non pas https://www.example.com/index.html
Le format AMP est-il géré par RM Tech ?
Réponse rapide : le format AMP n’est pas géré, dans la plupart des cas.
Réponse longue :
- Nous ignorons la balise <link rel=amphtml> au sens où nous n’allons pas crawler les URL au format AMP indiquées dans ces balises.
- Mais il est possible qu’elles soient crawlées si le serveur redirige une page HTML vers une page AMP, ou si une page HTML fait un lien ou indique en URL canonique une page AMP.
- Si la page AMP indique en URL canonique une autre URL (celle au format HTML), alors la page AMP ne sera pas considérée comme indexable, si bien qu’elle sera ignorée dans la plupart des analyses.
- Cela étant les performances des pages AMP (via Google Analytics et Google Search Console) sont exploitées par nos outils (à condition évidemment que la balise soit présente).
- Il existe 2 cas où un site au format AMP est géré par nos outils :
- le site n’a que des pages AMP et aucune HTML
- le serveur ne fait pas de redirection vers les pages AMP (seules les pages HTML sont crawlées). Généralement dans ce cas il faut préciser un user-agent desktop au lancement de l’outil.
Remarque : dans aucun cas RM Tech ne fait d’analyse pour savoir si votre implémentation des pages AMP est conforme ou pas. Vous avez déjà ce genre d’information dans Search Console.
Autres
Comment personnaliser mes rapports en marque blanche ?
- En haut à droite, cliquez sur le menu pour accéder à votre compte.
- Cliquez ensuite sur « Éditer vos options de personnalisation (marque blanche) des rapports«
- Remplissez les informations dans le formulaire et cliquez sur le bouton pour les enregistrer
RM Console
Abonnements
C’est quoi un projet ?
- Chaque formule permet de gérer un certain nombre de projets
- Un projet peut concerner un site entier (il faut alors choisir une propriété Search Console qui couvre tout le site) ou bien une sous-partie d’un site (soit en choisissant une propriété Search Console restreinte à un sous-domaine ou à un répertoire du site, soit en appliquant des filtres)
- Un projet est lié à une (seule) propriété Search Console (et donc à un seul nom de domaine au maximum)
- Si vous n’avez pas accès à la propriété Search Console du site à étudier, vous ne pouvez pas utiliser RM Console
- Si vous avez un site multilingue (avec chaque langue en répertoire à la racine), vous pouvez suivre l’ensemble dans un seul projet (et exploiter les groupes de pages pour avoir des détails par langues) ou bien avec un projet pour chaque langue (ce qui est nettement plus pratique).
- En cas de changement de nom de domaine de votre site, contactez-nous pour modifier le nom de domaine (et la propriété Search Console) dans les paramètres du projet.
- Vous pouvez supprimer un projet à tout moment. Il vous sera demandé de le confirmer à nouveau, car aucune récupération n’est possible une fois la suppression effectuée. En supprimant un projet, vous libérez un « emplacement » dans votre formule, ce qui vous permet d’en créer un nouveau immédiatement.
Comment fonctionne la formule gratuite ?
- Aucune carte bancaire n’est demandée
- Durée : la version gratuite est valable 60 jours. Elle ne peut pas être renouvelée.
- Un utilisateur ne peut profiter qu’une seule fois de la version gratuite
- A tout moment pendant la version gratuite, vous pouvez souscrire à une offre payante. Dans ce cas, votre projet sera conservé et votre offre gratuite sera transformée en offre payante.
- Une fois que les 60 jours sont passés, le projet est supprimé et rien n’est récupérable. Si vous souscrivez à une formule payante après ces 60 jours, vous démarrez de zéro.
- En formule gratuite, chaque site et compte Google ne peuvent être utilisés qu’une seule fois, tous comptes MyRankingMetrics confondus.
Comment fonctionne chaque formule payante ?
- L’abonnement démarre le jour du paiement (jour d’échéance) et se renouvelle de façon automatique (qu’il soit mensuel ou annuel)
- En abonnement mensuel, il est renouvelé le même jour du mois. S’il a été souscrit un 31, il sera renouvelé le dernier jour de chaque mois. Idem dans les autres cas spéciaux (29 ou 30 du mois).
- En abonnement annuel, il est renouvelé le même jour chaque année.
Quel intérêt ai-je à choisir Silver ou Gold plutôt que Bronze ?
Silver et Gold permettent de faire plus de choses :
- Optimisez beaucoup plus de pages par mois avec les modules « Pages à optimiser » et « Pages à relancer », ainsi que pour le maillage interne
- Profitez de l’indexation automatisée dans Bing et moteurs IA
- D’autres plafonds sont augmentés ou illimités (nb de mots-clés en suivi de position, nb de nouvelles requêtes sur lesquelles Google teste votre site), nb de groupes de pages
- Gérez plusieurs sites ou parties de sites dans les différents projets (5 projets pour Silver, 20 projets pour Gold). C’est très utile pour faire des analyses plus fines par sections de sites (multilingue, blog, etc.).
Comparez les possibilités de ces 3 formules dans le tableau des prix.
Puis-je changer mon ou mes projets pendant mon abonnement ?
- Oui vous pouvez changer de projet pendant votre abonnement. Pour cela, il suffit de supprimer le projet qui ne vous intéresse plus, cela libère alors une “place” dans votre abonnement que vous pourrez utiliser pour un autre projet.
- Vous pouvez faire ça autant de fois que vous voulez.
- C’est possible dans toutes les formules (même en Bronze), en mensuel ou annuel.
- Attention, quand vous supprimez un projet, il est impossible de le récupérer (même en demandant au support).
Peut-on s’abonner à plusieurs formules ?
- Oui ! Afin de profiter de la plus grande liberté de choix, vous pouvez souscrire à plusieurs formules en parallèle.
- Il est possible par exemple d’avoir un abonnement annuel à une formule ainsi qu’un abonnement mensuel à une autre formule.
- Chaque abonnement est indépendant des autres (mais ils sont tous regroupés dans votre compte), avec sa date d’échéance, sa période de renouvellement automatique, etc.
Comment résilier un abonnement ?
- Vous pouvez résilier l’abonnement à une formule à tout moment. Voici l’enchaînement des dates dans ce cas :
- du jour de la résiliation jusqu’au dernier jour de la période déjà payée (échéance) : l’abonnement reste actif et utilisable comme d’habitude
- le lendemain du jour d’échéance, le projet est désactivé. Plus aucune mise à jour n’a lieu mais les paramètres et les données déjà récoltées sont conservés.
- 30 jours après cette échéance, le projet est supprimé : aucun paramètre ni donnée n’est récupérable, même en payant à nouveau
- Si vous souscrivez à nouveau à une offre payante avant la fin des 30 jours de désactivation, vous pouvez récupérer vos projets et vos données. La mise à jour des projets démarre le jour de cette souscription. Il est possible que certaines données ne soient pas disponibles sur la période pendant laquelle aucune offre payante n’était active.
- Aucun remboursement ne peut avoir lieu en cas de résiliation.
Comment passer à une formule inférieure ?
- Vous pouvez à tout moment demander à rétrograder une formule pour passer à une formule inférieure.
- Au moment de faire ce changement, vous pouvez passer d’un abonnement mensuel à un annuel, ou ne rien changer.
- Le changement prendra effet le lendemain de la prochaine échéance. Si par exemple votre échéance est le 7 du mois et que vous demandez à rétrograder le 25, votre formule actuelle restera active jusqu’au 7, puis sera remplacée par la nouvelle.
- Dans le cas d’un abonnement annuel, prenez soin de surveiller la date de l’échéance. Il vaut mieux faire cette rétrogradation peu de temps avant l’échéance, et pas juste après (sinon vous devrez attendre presque un an pour qu’elle soit effective).
- Le jour de l’échéance ne sera pas modifié.
- Une formule inférieure ne pouvant pas gérer autant de projets, vous devrez supprimer les projets que vous ne souhaitez pas conserver.
- Les projets prévus pour être supprimés ne seront supprimés qu’au jour effectif de changement d’abonnement.
Comment passer à une formule supérieure ?
- Vous pouvez à tout moment demander à changer de formule pour passer à une formule supérieure.
- Si votre abonnement actuel est mensuel, vous pouvez rester en mensuel ou passer en annuel.
- Si votre abonnement actuel est annuel, le nouvel abonnement restera en annuel.
- Pour effectuer ce changement, un paiement sera effectué le jour de votre demande, qui deviendra le nouveau jour d’échéance de l’abonnement. Le montant est égal à celui de l’abonnement pour la formule supérieure choisie auquel est soustrait le pro-rata de ce qui restait, sur la base de 30 jours pour 1 mois. Prenons un exemple fictif :
- votre abonnement actuel est mensuel, d’un montant de 32€
- il reste 8 jours
- la somme au pro-rata est de 32€ x 8 / 30 = 8,53€
- quelle que soit la formule supérieure choisie, la 1ère échéance sera réduite de 8,53€
- Dès que le paiement est effectué, votre abonnement à l’ancienne formule est supprimé, remplacé par celui avec la nouvelle formule
Comment changer ma CB ?
- Vous pouvez modifier les informations de votre paiement mensuel par CB à partir de la page listant vos abonnements
- Sur cette page, il y a une liste de vos abonnements : choisissez l’abonnement pour lequel vous souhaitez modifier votre CB dans cette liste en cliquant le lien « voir » dans la colonne Détails
- Vous arrivez alors sur une page où se trouve un bouton pour « modifier le moyen de paiement »
Visibilité IA, crédits IA
Quelle est la différence entre les crédits IA Standard et Premium ?
| Crédits IA Standard | Crédits IA Premium |
|---|---|
| Ils sont liés à l’abonnement | Ils s’achètent de façon indépendante de l’abonnement |
| Ils sont renouvelés chaque mois, le jour du renouvellement de l’abonnement (même en facturation annuelle). Les crédits non utilisés pendant le mois ne sont pas reportables. | Durée de validité : à vie (aucune limite) |
Les 2 types de crédits IA peuvent être utilisés dans les outils qui nécessitent des crédits IA. Par exemple, ils permettent d’envoyer des questions sur ChatGPT ou Gemini et d’analyser les réponses.
Combien puis-je gérer de questions avec les crédits IA ?
Le nombre de crédits IA décomptés par question dépend du moteur IA utilisé et plus précisément du modèle. Voyez les détails ici.
D’où viennent les questions du module visibilité IA ?
Le module visibilité IA propose un assistant d’analyse de marque. Il suggère des thèmes correspondant aux produits et services de la marque choisie, adaptés aux personas, puis des questions pour chaque thème. Les questions correspondent à la phase finale du parcours d’achat (BOFU), quand l’utilisateur cherche à effectuer une transaction. C’est donc majeur que votre marque soit mentionnée dans les réponses des IA.
À quelle fréquence les questions sont-elles envoyées aux moteurs IA ?
Vous pouvez choisir et modifier la fréquence pour chaque question, ou pour tout un lot de questions (bulk) :
- 1 seule fois
- 1 fois par mois
- 1 fois par semaine
- 1 fois par jour
Pourquoi utiliser l’API et pas le scraping ?
Nous avons choisi d’utiliser l’API plutôt que le scraping car nous souhaitons respecter les conditions d’utilisation de ChatGPT et Gemini.
Par exemple, ChatGPT indique explicitement que le scraping est interdit : « Ce que vous ne pouvez pas faire » : « Extraire automatiquement ou par programme des données ou des Résultats » (source FR ou EN).
Outre l’aspect éthique, se baser sur le scraping implique un risque que l’outil ne soit plus disponible un jour. Soit car le scraping devient techniquement trop complexe voire impossible, soit pour des raisons juridiques (par exemple, Google poursuit en justice un outil qui scrape ses résultats).
Concernant la question de la personnalisation des résultats, le scraping ne permet pas d’obtenir les mêmes résultats que les utilisateurs. L’API non plus, mais c’est factuellement impossible d’y parvenir avec le scraping. Les données collectées varient considérablement d’un utilisateur à l’autre, car elles tiennent compte de leur historique de recherche, de leur emplacement géographique et de leurs données démographiques. Avec le scraping, il faudrait créer autant de comptes ChatGPT et Gemini (Google) qu’il existe de variantes de tous les personas de toutes les marques étudiées par l’outil, pour tous les lieux, avec tous leurs historiques…
Combien peut-on gérer de suivis de marques dans l’outil ?
Il n’existe aucune limite dans le nombre de marques que vous pouvez gérer dans l’outil de visibilité IA. Vous pouvez même créer plusieurs analyses d’une même marque (ce qui est indispensable quand elle adresse des marchés différents avec des concurrents différents).
Indexation Bing, ChatGPT, Perplexity…
Comment sont choisies les URL à envoyer pour indexation et dans quel ordre ?
L’outil se base sur plusieurs critères afin de prioriser les URL qui ont le plus besoin d’être indiquées à Bing en mode « push ». Voici les priorités décroissantes :
- les URL fournies en direct dans le formulaire (ou via un fichier texte) sont prioritaires car ça permet de gérer les urgences
- les URL détectées comme importantes en ce moment (même si le contenu n’a pas été modifié), pour leur donner un coup de projecteur
- les URL récemment créées ou modifiées (seulement si vous fournissez un ou des fichiers sitemaps ou RSS et qu’ils indiquent la date pour chaque URL)
- les URL trouvées dans l’audit RM Tech (si vous en avez indiqué un)
Toutes ces URL sont d’abord ajoutées en file d’attente, puis envoyées à Bing au fur et à mesure.
Combien d’URL peut-on envoyer chaque jour pour indexation Bing ?
La file d’attente est traitée plusieurs fois par jour par contre le nombre d’URL envoyées en « push » dépend de votre abonnement et de l’API utilisée :
- Bronze : 15 URL maximum par jour
- Silver et Gold :
- avec IndexNow : 100 000 URL maximum par jour
- avec Submission API : 10 000 URL maximum par jour
Maillage interne
Ne ratez pas notre guide pour optimiser le maillage interne.
Que faut-il pour utiliser l’outil de maillage interne ?
- L’outil de maillage interne est situé dans RM Console, il faut donc disposer d’un abonnement (Bronze au minimum)
- L’Intelligence Artificielle utilisée dans cet outil nécessite des données détaillées sur les pages du site. Celles-ci sont récoltées et calculées dans un audit RM Tech. Pour fournir des résultats pertinents, les données doivent être récentes (1 mois maximum).
- Il faut donc disposer d’un audit RM Tech avec annexes (un pré-audit n’est pas suffisant) de moins d’un mois du site concerné.
- Le prix de l’audit RM Tech permettant d’obtenir la data nécessaire pour “nourrir” l’IA dépend du nombre d’URL du site.
Peut-on utiliser l’outil de maillage interne pour optimiser une page qui reçoit déjà un lien depuis le menu ?
- Si la page cible reçoit déjà un lien dans le menu, toutes les pages du site incluant ce menu lui font donc déjà un lien, si bien que l’outil ne peut pas trouver de page où vous pourriez ajouter un lien.
- C’est possible si vous adaptez d’abord votre site, comme expliqué ci-après
Maillage interne : pourquoi faut-il un audit RM Tech récent ?
L’Intelligence Artificielle utilisée dans cet outil nécessite des données détaillées sur les pages du site. Ces données sont récoltées et calculées par RM Tech, il s’agit de QualityRisk, de tout ce qui a un rapport avec le maillage interne et la profondeur, ainsi que des données liées aux performances des pages (issues de Google Search Console).
Pour fournir des résultats pertinents, les données doivent être récentes (1 mois maximum).
Pour utiliser l’outil de maillage, vous devez donc disposer d’un audit RM Tech avec annexes du site concerné (un pré-audit n’est pas suffisant) de moins d’un mois.
Maillage interne : pourquoi tenez-vous compte uniquement du 1er lien dans une page ?
Si une page A fait un lien vers une page B dans le menu, et un autre lien toujours vers la page B dans le corps de la page, alors RM Tech ne tient compte que du 1er lien trouvé dans l’ordre du code source HTML. En d’autres termes, pour cet exemple, l’ancre du lien prise en compte est celle du lien situé dans le menu.
Comme de nombreux autres experts SEO (voyez cet exemple), nous pensons que ce fonctionnement est celui de Google, ou qu’il en est très proche. Voilà pourquoi nos outils fonctionnent de cette manière.
Maillage interne : pourquoi ne puis-je pas choisir comme URL cible une URL présente dans le menu ?
Si vous demandez à l’outil de trouver des liens vers une page cible présente dans le menu (ou le pied de page, ou une barre latérale), alors il risque de ne rien trouver. En effet, toutes les pages du site font déjà un lien vers la page cible.
Maillage interne : comment optimiser une page cible présente dans le menu ?
Si la page cible reçoit un lien depuis le menu, l’outil ne peut pas trouver de page source qui ne lui fait pas déjà un lien. Il faut donc choisir une ou plusieurs des solutions suivantes (liste non exhaustive) :
- Avoir un menu totalement différent dans le blog (ou une autre section du site) : c’est généralement la meilleure solution, et la plus simple
- Réduire le nombre de liens du menu (les pages qui n’y seront plus pourront être optimisées par le maillage interne)
- Ne pas afficher tous les liens du menu en entier dans tous les cas : par exemple, quand on est dans une catégorie, seuls les liens des sous-catégorie de cette catégorie sont présents dans le menu, mais pas les autres
- Déplacer le menu à la fin du code HTML : ceci ne permettra que de faire varier les ancres, mais vous devrez le faire vous-même, car l’outil de maillage continuera de considérer que la page cible reçoit déjà un lien
- Obfusquer les liens : cela consiste à modifier le code HTML pour remplacer les balises <a href> du menu par d’autres balises comme <span>
Attention, ces modifications peuvent avoir des impacts forts sur votre site et son SEO. Nous ne pouvons pas vous garantir que cela fonctionnera bien dans votre cas. C’est à vous de prendre les bonnes décisions.
Maillage interne : pourquoi presque toutes les pages cibles proposées ont un score d’intérêt très faible ?
Le score noté « Intérêt » pour chaque page est basé sur une échelle relative, car la valeur dépend de la 1ère page.
Nous attribuons 1000 points à la 1ère page et ensuite tout est relatif par rapport au potentiel de cette page. S’il y a un énorme écart entre la 1ère page et les autres, ça masque des choses c’est vrai, mais ça n’enlève rien au classement des pages qui suivent.
Si vous ajoutez assez de liens vers la page qui a un intérêt de 1000, et que vous faites un nouvel audit RM Tech, alors vos prochaines analyses de maillage interne montreront d’autres scores d’intérêt.
Pages à relancer
À quelle fréquence faut-il utiliser ce module ?
Comme celui sur les pages à optimiser, nous conseillons de le lancer au moins 1 fois par mois (davantage si vous publiez souvent du contenu).
En effet, chaque recherche de pages à relancer à fort potentiel SEO se base sur l’état actuel des pages, aussi bien en termes d’optimisation (vu par l’audit RM Tech) qu’en termes de performances (trafic et mots-clés selon Search Console).
Les résultats changent donc tout le temps. Des pages non trouvées un jour par ce module peuvent être identifiées la semaine suivante si leur déclin s’est prolongé ou accentué, ou si leur degré d’optimisation sur le site a changé (par exemple le maillage interne, qui peut évoluer automatiquement).
Pourquoi aucune page à relancer n’a été trouvée ?
Notre algorithme basé sur des données précises ainsi que sur l’IA est prévu pour repérer les pages en déclin ayant un fort potentiel SEO. En d’autres termes, des pages qui peuvent à nouveau générer un bon trafic organique si vous les mettez à jour et les retravaillez.
Si aucune page à relancer n’a été trouvée, c’est finalement bon signe pour vous ! Cela signifie que vous optimisez bien votre site ou qu’il est globalement en croissance.
Il existe néanmoins d’autres raisons :
- le site dispose d’un historique insuffisant dans Google Search Console (il faut 16 mois)
- le trafic des pages (clics GSC) est trop faible, notamment l’année précédente
- des filtres dans votre projet RM Console restreignent l’analyse (par exemple à un pays et/ou à une partie du site)
- l’audit RM Tech que vous avez sélectionné pour la recherche ne couvre pas l’ensemble du site
- pour votre recherche de pages à relancer, vous avez appliqué une restriction sur les URL du site (motifs d’inclusion ou exclusion, ou regex)
D’où viennent les mots-clés proposés ?
Tous les mots-clés listés dans le module Pages à relancer proviennent de Google Search Console.
C’est très important car cela signifie que ces mots-clés sont ceux utilisés par vos personas, votre audience. Ils sont souvent plus pertinents que les mots-clés que des outils généralistes peuvent vous lister (car dans ce cas ils ne sont pas aussi bien adaptés à votre audience).
Que faut-il pour utiliser l’outil Pages à relancer ?
- L’outil Pages à relancer est situé dans RM Console, il faut donc disposer d’un abonnement (Bronze au minimum)
- Il faut disposer de 16 mois de données dans GSC, d’un trafic suffisant et de pages en déclin sur des mois. Vous pouvez tester gratuitement 1 fois.
- L’Intelligence Artificielle utilisée dans cet outil nécessite des données détaillées sur les pages du site. Celles-ci sont récoltées et calculées dans un audit RM Tech. Pour fournir des résultats pertinents, les données doivent être récentes ( 1 mois maximum).
- Il faut donc disposer d’un audit RM Tech avec annexes (un pré-audit n’est pas suffisant) de moins d’un mois du site concerné.
- Le prix de l’audit RM Tech permettant d’obtenir la data nécessaire pour “nourrir” l’IA dépend du nombre d’URL du site.
Pages à optimiser
À quelle fréquence faut-il utiliser ce module ?
Comme celui sur les pages à relancer, nous conseillons de le lancer au moins 1 fois par mois (davantage si vous publiez souvent du contenu).
En effet, chaque recherche de pages à optimiser à fort potentiel SEO se base sur l’état actuel des pages, aussi bien en termes d’optimisation (vu par l’audit RM Tech) qu’en termes de performances (trafic et mots-clés selon Search Console).
Les résultats changent donc tout le temps. Des pages non trouvées un jour par ce module peuvent être identifiées quelques semaines plus tard. Cela dépend de leurs performances ainsi que de leur degré d’optimisation sur le site a changé (par exemple le maillage interne, qui peut évoluer automatiquement).
Pourquoi aucune page à optimiser n’a été trouvée ?
Notre algorithme basé sur des données précises ainsi que sur l’IA est prévu pour repérer les pages ayant un fort potentiel SEO. En d’autres termes, des pages dont le gain en trafic organique est le plus élevé si vous les retravaillez.
Si aucune page à optimiser n’a été trouvée, c’est finalement bon signe pour vous ! Cela signifie que vous optimisez bien votre site. Il existe néanmoins d’autres raisons :
- le trafic des pages (clics GSC) est trop faible sur les 12 derniers mois
- des filtres dans votre projet RM Console restreignent l’analyse (par exemple à un pays et/ou à une partie du site)
- l’audit RM Tech que vous avez sélectionné pour la recherche ne couvre pas l’ensemble du site
- pour votre recherche de pages à relancer, vous avez appliqué une restriction sur les URL du site (motifs d’inclusion ou exclusion, ou regex)
D’où viennent les mots-clés proposés ?
Tous les mots-clés listés dans le module Pages à optimiser proviennent de Google Search Console.
C’est très important car cela signifie que ces mots-clés sont ceux utilisés par vos personas, votre audience. Ils sont souvent plus pertinents que les mots-clés que des outils généralistes peuvent vous lister (car dans ce cas ils ne sont pas aussi bien adaptés à votre audience).
Quelle est la différence entre Pages à relancer et Pages à optimiser ?
Le module Pages à relancer se concentre exclusivement sur les pages en déclin depuis des mois. Il nécessite une plage de 16 mois de données afin de pouvoir comparer les derniers mois à la période équivalente de l’année d’avant.
Le module Pages à optimiser peut concerner des pages en déclin ou des pages en croissance, ce n’est pas un critère. Par contre, seules les pages dont l’optimisation serait la plus profitable sont listées. La période d’analyse couvre les 12 derniers mois.
Nous vous conseillons de toujours commencer par le module Pages à relancer.
- si des pages sont suggérées, alors mieux vaut commencer par les retravailler
- ensuite, ou bien si aucune page à relancer n’est trouvée, enchaînez par Pages à optimiser
Que faut-il pour utiliser l’outil Pages à optimiser ?
- L’outil Pages à optimiser est situé dans RM Console, il faut donc disposer d’un abonnement (Bronze au minimum)
- Il faut disposer d’au moins 12 mois de données dans GSC et d’un trafic suffisant. Vous pouvez tester gratuitement 1 fois.
- L’Intelligence Artificielle utilisée dans cet outil nécessite des données détaillées sur les pages du site. Celles-ci sont récoltées et calculées dans un audit RM Tech. Pour fournir des résultats pertinents, les données doivent être récentes ( 1 mois maximum).
- Il faut donc disposer d’un audit RM Tech avec annexes (un pré-audit n’est pas suffisant) de moins d’un mois du site concerné.
- Le prix de l’audit RM Tech permettant d’obtenir la data nécessaire pour “nourrir” l’IA dépend du nombre d’URL du site.
Compte My Ranking Metrics
Association avec un compte Google
Pourquoi associer mon compte My Ranking Metrics à mon compte Google ?
Pour RM Console, les données proviennent de Google Search Console, donc c’est indispensable.
Pour RM Tech, RM Sitemaps et RM Pagination :
En autorisant My Ranking Metrics à récupérer des données dans Google Search Console, vous profitez du couplage de ces données avec celles issues de notre crawl. Grâce à ça, vos rapports d’audit s’enrichissent de données et surtout de fonctionnalités avancées comme :
- le calcul de l’indice Page Zombie (nécessite Google Search Console en choisissant une période de 1 an de données)
- les pages ayant le plus de facilité à passer de la page 2 des résultats Google à la page 1 (nécessite Google Search Console)
Nos outils n’ont plus besoin de Google Analytics, tout vient de Search Console.
Remarque : ce couplage est offert, il ne consomme aucun crédit.
Comment associer mon compte Google pour les données Search Console ?
Si vous ne l’avez pas encore fait, allez dans votre compte My Ranking Metrics et cliquez sur « Gestion des comptes Google » puis sur le bouton « Ajouter un nouveau compte ». Vous devrez accepter les demandes d’autorisation de Google.
Si vous l’avez déjà fait et que cela ne fonctionne pas bien pour un ou plusieurs de vos comptes Google :
- allez sur https://www.google.fr et vérifiez que vous êtes connecté au compte Google qui dispose des accès Google Search Console nécessaires
- rendez-vous sur https://myaccount.google.com/permissions pour supprimer l’autorisation accordée à My Ranking Metrics (si jamais il y en a déjà une d’enregistrée)
- allez dans votre compte My Ranking Metrics et cliquez sur « Gestion des comptes Google »
- repérez le tableau « Liste des comptes Google déjà associés à votre compte My Ranking Metrics »
- pour la ligne correspondant au compte Google qui pose problème, cliquez sur « Supprimer »
- maintenant, ajoutez à nouveau ce compte Google en cliquant sur le bouton « Ajouter un nouveau compte »
Quelles données sont récupérées par My Ranking Metrics ?
Il s’agit des données concernant la performance des pages et des requêtes selon Google Search Console, à savoir les 4 métriques clics, impressions, CTR moyen et position moyenne.
Mon login et mon mot de passe seront-ils connus par My Ranking Metrics ?
Non bien entendu, nous n’avons accès à aucun moment à vos données de connexion. Nous utilisons le mécanisme officiel de Google (API) pour vous demander l’autorisation d’accéder au compte. Nous n’avons accès aux données qu’en simple lecture seule, sans aucune modification possible. Voyez à quoi ça ressemble :
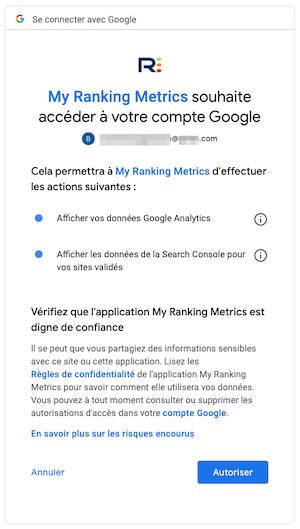
A tout moment, vous pouvez vérifier à quoi My Ranking Metrics a accès en allant sur cette page (en vous assurant d’être bien connecté au bon compte Google). Voyez à quoi ça ressemble :

Comment associer mon compte My Ranking Metrics à mon compte Google ?
Vous pouvez le faire soit au 1er lancement d’un audit complet, soit en allant dans votre compte (lien en haut à droite) rubrique « Gérer vos comptes Google ».
C’est également à faire pour créer un projet dans RM Console.
Si cela ne fonctionne pas, essayez de procéder comme suit :
- allez dans votre compte My Ranking Metrics, rubrique « Gérer vos comptes Google »
- si le compte Google concerné est déjà listé, cliquez sur le lien X pour supprimer l’association (et validez la demande de confirmation)
- révoquez également l’autorisation accordée à My Ranking Metrics dans votre compte Google, en cliquant sur ce lien (en vous assurant d’être bien connecté au bon compte Google)
- recommencez l’association et l’autorisation
Comment changer mes données de facturation ?
Une fois qu’elles ont été fournies, vous ne pouvez plus les modifier vous-mêmes. Dans ce cas, veuillez nous contacter en détaillant tous les changements que vous souhaitez.
Fonctionnement de nos outils d’audit
Les règles qui suivent concernent les outils basés sur un crawl du site (RM Tech, RM Sitemaps et RM Pagination).
- Quelles URL sont crawlées (et comptent donc pour les crédits, avec la règle 1 URL crawlée = 1 crédit) ?
- dans RM Tech : nous partons de l’URL de départ. Ensuite, les URL crawlées sont celles trouvées dans les liens (<a href>), les URL canoniques ou via les redirections.
- toujours dans RM Tech, si l’option d’analyse des images est activée, chaque image trouvée (balise <img> avec une URL dans l’attribut src) compte 1 crédit
- dans RM Sitemaps : nous crawlons uniquement celles fournies dans les sitemaps
- dans RM Pagination : c’est presque comme dans RM Tech. Nous partons de l’URL de départ. Ensuite, les URL crawlées sont celles trouvées dans les liens (<a href>), dans les URL canoniques ou via les redirections. Par contre, les URL reconnues comme étant des URL de pagination sont crawlées même si elles sont spécifiquement interdites de crawl (le but étant d’analyser à 100% comment est implémentée la gestion de la pagination sur le site). Si vous ne voulez vraiment pas qu’elles soient crawlées, il suffit d’utiliser le motif d’exclusion.
- Nous respectons le fichier robots.txt de la même façon que Google (avec quelques particularités par rapport au standard)
- Nous tenons compte également :
- des balises meta robots
- des directives passées dans l’entête HTTP (pour l’URL canonique ou pour les directives d’indexation et de suivi des liens)
- Le User-Agent de notre crawler peut être sélectionné dans une liste prédéfinie, ou personnalisé, ou vide. Par défaut, il s’agit de celui de Chrome pour smartphone. Si votre site en version mobile redirige « de force » les utilisateurs sur la version AMP, l’audit ne pourra pas s’exécuter correctement et dans ce cas il vaut mieux paramétrer un User-Agent en version ordinateur.
- Nous ne gérons pas :
- les cookies
- le javascript (et ajax ou équivalent) : il n’est pas exécuté
- le CSS
- le fait d’avoir une version mobile d’une page à une URL distincte (les URL mobiles peuvent être crawlées mais risquent d’être indiquées comme non indexables en raison de leur URL canonique)
- le format AMP, dans la plupart des cas. En effet, nous ignorons la balise <link rel=amphtml> donc a priori nous ne crawlons pas les URL au format AMP indiquées dans ces balises. Mais il est possible qu’elles soient crawlées si le serveur redirige une page HTML vers une page AMP, ou si une page HTML fait un lien ou indique en URL canonique une page AMP. Si la page AMP indique en URL canonique une autre URL (celle au format HTML), alors la page AMP ne sera pas considérée comme indexable, si bien qu’elle sera ignorée dans la plupart des analyses. Cela étant les performances des pages AMP (via Google Analytics et Google Search Console) sont exploitées par nos outils (à condition évidemment que la balise <link rel=amphtml> soit présente). Il existe 2 cas où un site au format AMP est géré par nos outils : soit si le site n’a que des pages AMP et aucune HTML, soit si le serveur ne fait pas de redirection vers les pages AMP (seules les pages HTML sont crawlées, généralement il faut préciser un user-agent desktop).
- Nous ne suivons pas :
- les formulaires
- les redirections meta
- les liens nofollow, sauf si l’option de suivi est activée au lancement (pour les liens internes, ou pour les liens externes, ou pour les 2)
- si un lien autorisé au crawl pointe vers une URL qui n’est pas du HTML (par exemple un PDF mais aussi une image), cette URL sera crawlée. Par contre, l’essentiel de l’analyse se faisant sur les pages HTML, ces URL seront exclues de la plupart des éléments de l’audit.
- si l’option d’analyse des images est activée, les images étudiées sont celles trouvées dans l’attribut src de la balise <img>, quand cet attribut indique une URL (donc pas sous la forme data:xxx). Les autres attributs de la balise <img> sont ignorés, tout comme les images définies exclusivement par les CSS.
- Pour calculer le nombre de liens entrants internes d’une page (backlinks) :
- nous cherchons les pages (indexables uniquement) qui ont une balise <a href> qui pointe vers la page qu’on étudie (de façon directe, sans redirection)
- si une page A fait un lien vers elle-même, cela ne compte pas comme un backlink
- si une page A fait un lien vers B qui redirige vers C, alors A n’est pas comptée comme un backlink de C
- si une page A fait plusieurs liens vers une même page B, alors cela compte comme un seul backlink. Attention : dans ce cas, seul le 1er lien est pris en compte, donc s’il est nofollow, nous considérons que la page A ne fait aucun lien vers la page B.
- si une page A est non indexable, aucun des liens qu’elle fait n’est pris en compte
- l’URL canonique n’est pas prise en compte ici, uniquement les liens avec une balise
Autres questions ?
Si vous avez d’autres questions, posez-les dans le formulaire de contact.